


Robots.txt在SEO中有何作用?如何正确配置?

在现代网站管理中,Robots.txt文件扮演着不可或缺的角色。作为一种标准的文本文件,它能够指导搜索引擎如何抓取和索引网站内容,从而对搜索引擎优化(SEO)产生重要影响。本文将探讨Robots.txt的定义、历史背景、基本功能及其在SEO中的重要性,并指导如何正确配置该文件。
什么是robots.txt文件?
robots.txt的定义
Robots.txt是一个位于网站根目录下的文本文件,用于告知搜索引擎爬虫哪些页面可以被抓取,哪些页面应该被忽略。该文件通过简单的语法结构,使用具体的指令来控制搜索引擎的行为。
robots.txt的历史背景
Robots.txt的概念最早提出于1994年,随着互联网的发展,网站数量急剧增加,网站管理员便需要一种方法来管理搜索引擎对其网站内容的访问。自那时起,Robots.txt便成为遵循网络爬取规范的重要工具,广泛应用于各种网站,以确保搜索引擎能够高效地抓取和索引内容。
robots.txt的基本功能
Robots.txt的基本功能是控制搜索引擎爬虫的抓取行为。通过该文件,网站管理员可以允许或禁止爬虫访问特定的目录或页面,从而减少不必要的服务器负担,实现更好的资源管理。
robots.txt在SEO中的重要性
控制搜索引擎爬取
Robots.txt能够有效地控制哪些页面被搜索引擎抓取。在SEO策略中,网站管理员可以将关键页面与不重要的页面分开,从而集中搜索引擎的注意力在高价值的内容上,提高这些页面的排名潜力。
防止重复内容抓取
重复内容是SEO中的一个常见问题,可能导致搜索引擎将其排名降至较低水平。通过合理配置Robots.txt,网站管理员可以防止搜索引擎抓取重复或相似的内容,从而避免由于内容重复而带来的排名损失。
提高网站加载速度
一个良好的Robots.txt配置可以减少搜索引擎对无关页面的抓取,从而减少对服务器的请求次数。这不仅提高了网站性能,还能改善用户体验,提高网站的加载速度。
如何创建和配置robots.txt文件
基本语法和规则
Robots.txt文件的基本语法和规则相对简单。一般格式为:
User-agent: [搜索引擎爬虫名称] Disallow: [不允许抓取的路径] Allow: [允许抓取的路径]
例如,旨在阻止所有搜索引擎爬虫访问特定目录的指令可以写为:
User-agent: * Disallow: /private/
常见的指令
在创建Robots.txt文件时,有几种常用指令需要了解:
User-agent: 指定适用的搜索引擎爬虫。Disallow: 指定不希望被抓取的路径。Allow: 明确允许抓取的路径,优先级高于Disallow指令。
配置实例解析
假设一个网站希望阻止爬虫访问其后台,但允许访问所有其他页面,robots.txt可以配置如下:
User-agent: * Disallow: /admin/ Allow: /
通过这种配置,所有搜索引擎爬虫将被禁止访问/admin/目录,但仍可以抓取网站的其他部分。这类配置确保了重要内容的可见性,同时保护敏感区域不被索引。
总结而言,Robots.txt文件是网站优化中一个至关重要的工具。通过合理配置,不仅能有效管理搜索引擎的抓取行为,还有助于提高网站的SEO效果。网站管理员应定期审查和更新该文件,以确保其内容和指令的准确性。
robots.txt文件的最佳实践
有效阻止搜索引擎爬取敏感内容
在配置robots.txt文件时,确保有效阻止搜索引擎爬虫抓取敏感内容是至关重要的。例如,网站的管理后台、用户隐私页面或尚未完成的草稿内容,通常不希望被搜索引擎索引。通过在robots.txt中使用Disallow指令,可以指定这些页面或目录,防止爬虫访问,降低潜在的安全风险。
除了阻止访问这些敏感内容外,还应考虑使用合适的的User-agent指令来控制针对特定爬虫的访问。某些情况下,您可能希望只阻止某个搜索引擎的爬行,而允许其他搜索引擎抓取,从而实现更为灵活的管理。定期审查这些设置,以确认它们能 effectively 保护网站数据,是管理过程中不容忽视的一部分。
检测和测试robots.txt文件
配置完robots.txt文件后,检测和测试其有效性是不可或缺的步骤。许多搜索引擎提供了工具,可以用来验证robots.txt文件的配置是否正确。例如,Google Search Console中的Robots.txt测试工具,允许网站管理员模拟搜索引擎爬虫的行为,并查看是否会被允许或阻止访问特定页面。这可以帮助识别潜在的错误,确保所设定的规则如您所愿。
使用这样的测试工具后,可以分析爬虫如何理解您的配置,确认他们是否遵循robots.txt文件的指示。此外,及时监测网站的抓取报告,若发现有意想不到的行为(如预期外的页面被抓取),应及时回头检查robots.txt的配置和指令。
定期更新和维护robots.txt文件
随着网站内容的不断变化,定期更新和维护robots.txt文件显得尤为重要。您可能会添加新页面、删除旧页面或调整内容结构,因此适时调整robots.txt的配置,以确保其反映最新网站架构。保持文件的时效性,有助于更加有效地控制搜索引擎对新内容的抓取行为。
此外,建议在网站重大更新后,比如重新设计或内容迁移后,立即审查并更新robots.txt文件。这将有助于确保既有内容的可见性,同时有效防止敏感内容被抓取。与此同时,保持记录,了解每次更改的原因和结果,也能够在未来决策中提供参考。
常见的robots.txt配置错误及解决方案
错误的路径书写
在配置robots.txt时,常见错误之一是路径书写不正确。如果路径没有反映网站的实际结构,搜索引擎爬虫可能会因为找不到指定的文件或目录而无法执行预期的访问控制。例如,使用了错误的斜杠方向或者漏了某个子目录,这都会导致已设定的抓取规则无效。验证路径是否正确是避免这一类问题产生的关键。
为确保路径书写的准确性,网站管理员可以在实际浏览网站结构的同时,参考并核对robots.txt所定义的路径配置。此外,使用工具来检查和测试这些规则也能有效地帮助识别潜在问题。当发现错误时,及时修正,以确保搜索引擎能够正确遵循您所设定的访问规则。
使用不完整的指令
另一种常见的配置错误是使用不完整的指令,这可能会导致预期的效果无法实现。如果只有User-agent或者Disallow指令而没有适当配置其他指令,爬虫可能会无法正确理解访问规则,例如简单的忽略可能导致所有页面都被抓取。确保每一条指令都是完整且合理的,是有效进行访问控制的基础。
以此为例,如果您希望一个特定的搜索引擎爬虫完全停止访问某个目录,而只给其他爬虫开放该目录,您需要确保包含完整的User-agent和Disallow指令,以及你想要达成的任何Allow指令。不断审查指令并进行测试,是实现无缝配置的重要策略。
忽略规范化URL
在配置robots.txt时,许多人忽略了规范化URL的重要性。网站可能包含多个版本的相同页面,例如带有查询参数的URL、HTTP与HTTPS的版本、以及带有www与不带www的版本等。而不当的配置可能导致这些重复内容被不必要地抓取,影响SEO的效果。在robots.txt中明确指明这些规范化策略,可以帮助搜索引擎识别您希望关注的页面版本。
在robots.txt中通过合理的配置来禁止爬虫抓取重复的URL,是防止内容重复和维护网站排名的重要手段。始终要记得,尽管robots.txt是一种有效管理工具,结合其他SEO技术如301重定向,也可以帮助实现更为深入、全面的优化效果。定期对网站内容进行审核,并确保robots.txt文件能反映当前状态,是持续优化中不可或缺的一部分。
结合robots.txt与其他SEO工具的策略
与Google Search Console的结合
通过Google Search Console,网站管理员可以有效地监控和优化robots.txt的效果。该平台提供了Robots.txt测试工具,允许您模拟搜索引擎爬虫访问您的网站,并查看它们将如何解析您的robots.txt文件。这一功能使得您能及时发现配置中的错误或不当之处,从而有所调整,确保搜索引擎能够准确理解并遵循相关的抓取指令。
此外,Google Search Console还可以提供对网站抓取数据的深入分析,比如哪些页面被抓取、抓取的频率以及是否存在抓取错误。这对于优化robots.txt文件有重要指导意义。您可以根据抓取数据进行调整,比如增加对重要页面的抓取,或进一步限制对无关或者敏感页面的访问,从而实现更高效的SEO策略。
运用Sitemap提升SEO效果
Sitemap文件与robots.txt配合使用时,能够在SEO中发挥更大的作用。通过在robots.txt中指明Sitemap的路径,您可以引导搜索引擎更快地发现您希望它们关注的页面。例如,一个典型的robots.txt文件可包含如下指令:
Sitemap: https://www.example.com/sitemap.xml
这一指令确保爬虫能尽快找到Sitemap,从而提高重要内容被抓取和索引的可能性。Sitemap罗列了网站上所有希望被抓取的页面,帮助搜索引擎更有效地了解您的网站结构。结合robots.txt,两者能够形成一个完美的抓取策略,提升网站的整体SEO效果。
利用robots.txt进行A/B测试
Robots.txt还可以应用于A/B测试,帮助您评估不同页面或内容策略的效果。通过在robots.txt中灵活地修改页面访问权限,您可以控制不同版本的内容被抓取的频率,从而在不同版本之间进行有效比较。比如,您可以暂时禁止搜索引擎抓取某个新设计的页面,同时允许另一个版本继续索引。
在收集到足够的数据后,您可以分析不同版本的SEO表现,包括页面的流量、排名和用户互动等指标。这将使您能够做出更加明智的优化决策,集中精力在表现更佳的内容上,最终为用户提供更优质的体验。
结语与总结
归纳robots.txt的重要性
Robots.txt在网站管理和SEO中具有重要意义。它不仅能控制搜索引擎对内容的抓取行为,还能帮助提升网站 Performance 和用户体验。良好的robots.txt配置能够减少无效抓取,保证搜索引擎爬虫能集中精力抓取那些对提升排名至关重要的页面。与此同时,定期检查和更新该文件,则能确保其始终反映当前网站结构与内容。
强调正确配置的重要性
正确配置robots.txt文件至关重要。稍有不慎可能导致搜索引擎无法抓取关键页面,或反之,敏感页面却被非法索引。因此,网站管理员应谨慎设计robots.txt,遵循最佳实践,并结合其他SEO工具,确保文件的有效性与适用性。倘若出现了抓取错误,及时整顿将有助于维持网站优化成果。
鼓励持续学习和优化
随着搜索引擎算法的不断更新变化,掌握robots.txt的使用方法以及相关的SEO策略,实际上是一个持续的学习过程。在此过程中,定期分析抓取数据、评估效果、调整配置,都是不可或缺的环节。希望通过深入了解和合理运用robots.txt,大家都能在网站优化之路上不断进步,持续实现更加卓越的SEO效果。
热门推荐
更多案例-

2025-03-04
矿山设备行业谷歌SEO优化成功案例
read more客户背景客户是一家专注于矿山设备生产和销售的企业,主要产品包括破碎机、筛分设备、输送机等。客户希望通···
-
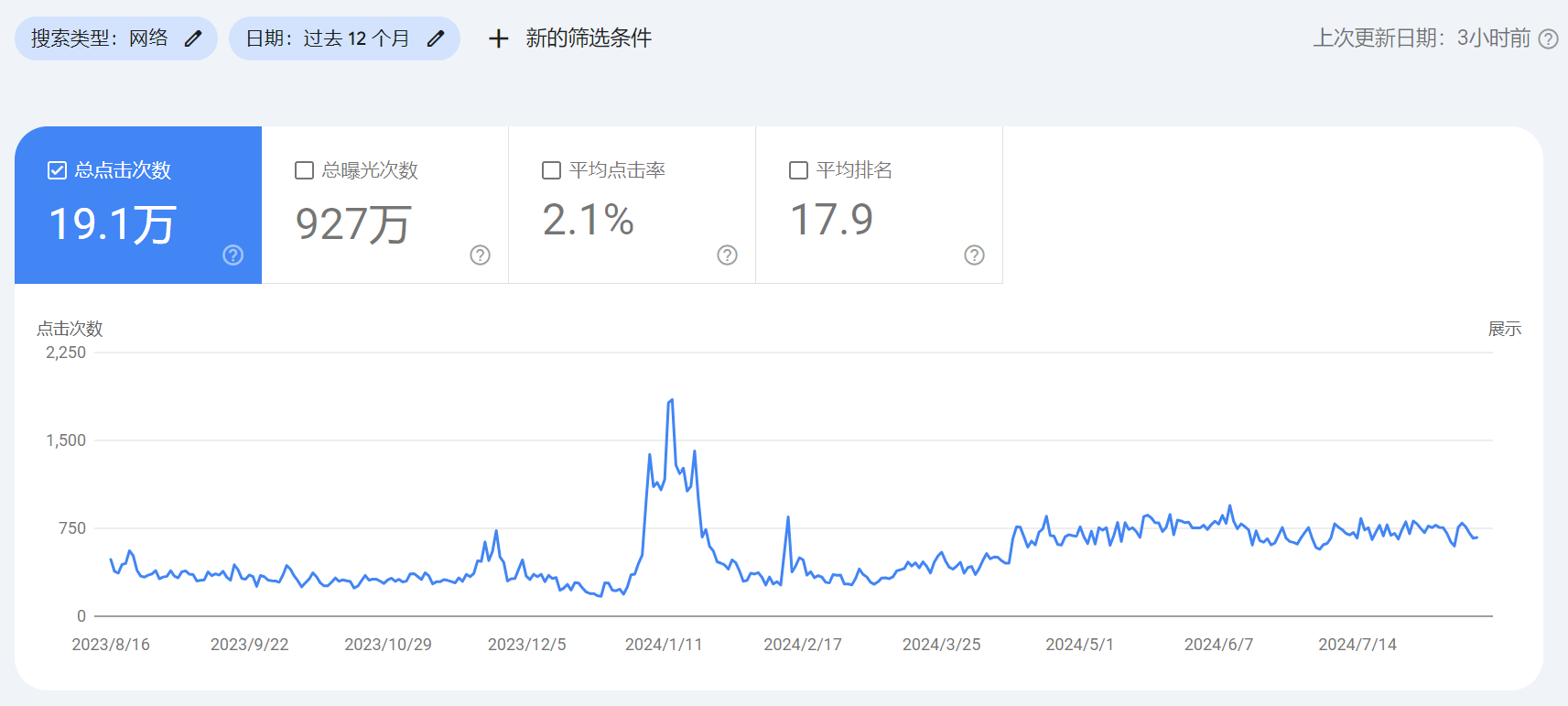
2025-03-04
户外动力设备行业谷歌SEO优化成功案例
read more客户背景该客户是一家专注于设计和制造功能齐全的户外动力设备的公司,产品包括割草机、发电机、吹雪机、庭···
-
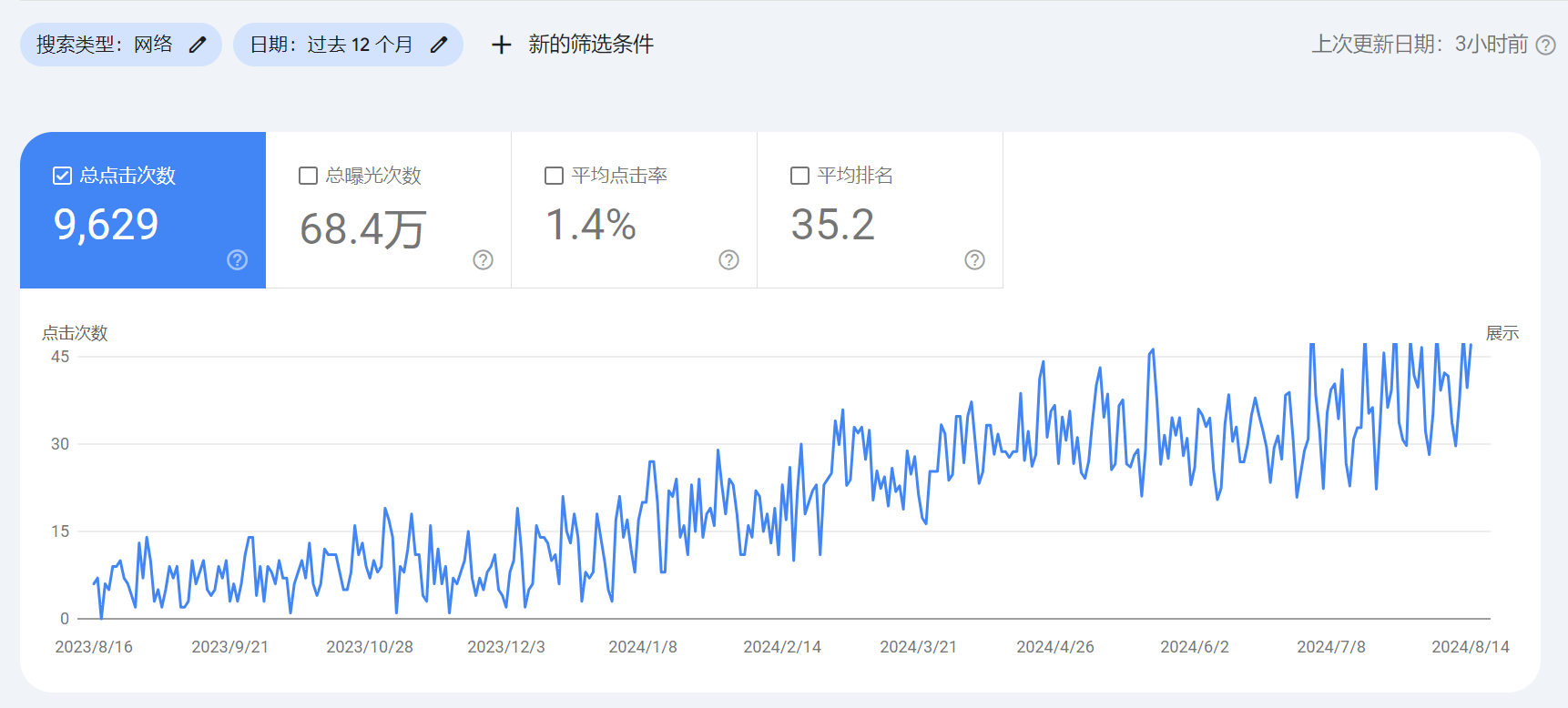
2025-03-04
家居装饰行业谷歌SEO优化成功案例
read more客户背景客户是一家专注于家居装饰产品的公司,主要产品包括墙板、吸音板、3D墙板、墙线、踢脚板、复合地板···
-
2025-03-04
家居装饰行业谷歌SEO优化成功案例
read more客户背景客户是一家专注于家居装饰产品的公司,主要产品包括墙板、吸音板、3D墙板、墙线、踢脚板、复合地板···